5.1. Property Sampling¶
5.1.1. Overview¶
Optrace approximates optical effects by utilizing an Unbiased Quasi Monte Carlo simulation. Inverse Transform Sampling is used as method for non-uniform random variable generation and Stratified Sampling as low discrepancy method for the generation of the initial uniform random variable.
A brief description of these terms:
Monte Carlo Simulation: An algorithm class that approximates a problem with many degrees of freedom by randomly choosing and simulating a subset of all property and variable combinations.
Quasi Monte Carlo Simulation: Monte Carlo Simulation, but the sampling is not truly random nor pseudo-random. Instead it has some underlying deterministic or semi-deterministic nature to it. See low-discrepancy methods below.
Unbiased and Biased Methods: For unbiased methods, the expected value of the results is without any systematic error and always equal to the true physical value. A biased simulation contains such a systematic deviation, but might considerably reduce visible noise or computation time (e.g., in neural network denoising). A more mathematical description of bias can be found here: [1]
Non-Uniform Random Variate Generation: Generating random numbers, while some numbers are more likely to be chosen than others. The probability distribution is non-uniform.
Low Discrepancy Method: Values from these methods only deviates weakly from an equidistribution. White noise is a high discrepancy method, as many samples are required to approximate a true equidistribution. A regular value grid is a zero discrepancy method, since the values are always regularly distributed. Low discrepancy methods can be seen as a compromise between these two, trying to create values that fill an interval or area more uniformly than random values, but are less “obviously deterministic” than simple grids. Important types of low discrepancy methods include Hamilton and Sobol sequences as well as lattice methods.
Stratified Sampling: One of many low discrepancy methods. Random values are chosen from a set of sub-groups. It is guaranteed that values are chosen from every sub-group (e.g. different intervals), but the values inside each sub-group are chosen randomly (e.g. random positions inside each interval). Details on the implementation in optrace are discussed in Section 5.1.5.
Inverse Transform Sampling: Generating non-uniform random numbers according to a known distribution function by utilizing the inverse transform method. Details on this method are discussed in Section 5.1.4. Important alternative sampling methods include: Importance Sampling, Rejection Sampling.
5.1.2. Ray Properties¶
When generating rays at the source, there are multiple properties and property distributions. The number of degrees of freedom is dependent on the source parameters.
The simplest case, with no degrees of freedom, is a monochromatic point source emitting parallel light with equal polarization. At the other end there is an area source with a broad spectrum, random polarization, an ray orientation dependent on the ray position and rays spreading randomly relative to this orientation inside some directional cone.
Symbol |
Description |
Comment |
Degrees of Freedom |
|---|---|---|---|
\(x,y\) |
Position |
Point Source, Line Source, Area Source |
0 - 2 |
\(\lambda\) |
Wavelength |
Monochromatic or spectrum |
0 - 1 |
\(P\) |
Power |
All rays have equal power |
0 |
\(s_0\) |
orientation vector |
Constant or position dependent |
0 - 2 |
\(s\) |
orientation vector distribution around \(s_0\) |
Constant or specified as 1-2 angle distributions |
0 - 2 |
\(E\) |
Polarization |
Constant or specified by angle distribution |
0 - 1 |
For properties with one or two degrees of freedom the initial uniform random variable is generating with stratified sampling in Section 5.1.5. So, for instance, for position sampling of an area the two dimensional stratified sampling creates the random variables \(\mathcal{U}_x,~\mathcal{U}_y\), which later are used as input for position sampling in Section 5.1.9.
5.1.3. Stochastic Sampling¶
In raytracing, a standard procedure is to randomize beam properties. Doing so, periodic artifacts and sampling errors are exchanged for noise. This approach is known as stochastic sampling [2].
One example is the sampling of a surface using a rectangular grid. Aliasing occurs with a violation of the sampling theorem and visible artifacts appear. The effect can be seen in [3], figure 4, and [4], slide 8.
However, if the rays are randomly distributed on the surface, the sampling theorem is still violated locally, but at random locations and with random severity due to the random spacing between the sampling points. For the observer, the resulting aliasing in the image comes across as noise.
5.1.4. Inverse Transform Sampling¶
The inverse transform sampling theorem [5] is applied to calculate a random variable \(\mathcal{T}_{[0,1]}\) with probability distribution function \(\text{pdf}(x)\) from a uniform random variable \(\mathcal{U}_{[0,~1]}\).
Here, \(\text{cdf}^{-1}(x)\) is the inverse cumulative distribution function. The cumulative distribution function \(\text{cdf}\) is defined as integral of a probability distribution function \(\text{pdf}\):
The sampling theorem can be generalized for sampling from an interval \([a,~b]\) of a function \(f(x)\) with
and with \(F(x)\) being injective \(\forall x \in [a, b]\), as:
This relation is also found in [5] under “Truncated Distributions” or in the last paragraph of [6].
5.1.5. Stratified Sampling¶
Perrier[7] examines and compares different low-discrepancy methods in his work in detail. Regarding simplicity, speed ([7], Figure 3.38), convergence ([7],Table 3.1), spectrum and discrepancy ([7], Figure 3.37) the stratified sampling method should be most suitable in our raytracer. This method is described in [7], pages 36-37, while another explanation can be found in [8] under the name Uniform Sampling + Jitter.
One dimension
In one dimension, the coordinate set \(\mathcal{X}_N\) with \(N\) values is built of equally spaced interval values with an additional dither having the maximum size of one interval spacing.
Next, the resulting values need to be shuffled randomly.
Two dimensions
For simplicity, a square grid is used for stratified sampling in two dimensions. Every integer number can be divided into a square and remaining non-square part. The remaining part gets distributed randomly inside the grid.
\(N\) points can be divided into a root number \(N_s = \lfloor\sqrt{N}\rfloor\) and a remaining term \(\Delta N = N - N_s\). A set of rectangular grid coordinates with \(N_s\) values in each dimension is added with a dither to produce a stratified sampled grid \(\mathcal{P}_G\).
The remaining points \(\mathcal{P}_\Delta\) are generated randomly inside the grid, being equivalent to white noise sampling:
The point set \(\mathcal{P}\) with size \(N\) is then the union of both:
The set \(\mathcal{P}\) then needs to be ordered randomly.
Comparison with simple sampling
A comparison to simple sampling (white noise generation) can be found in the following two figures.
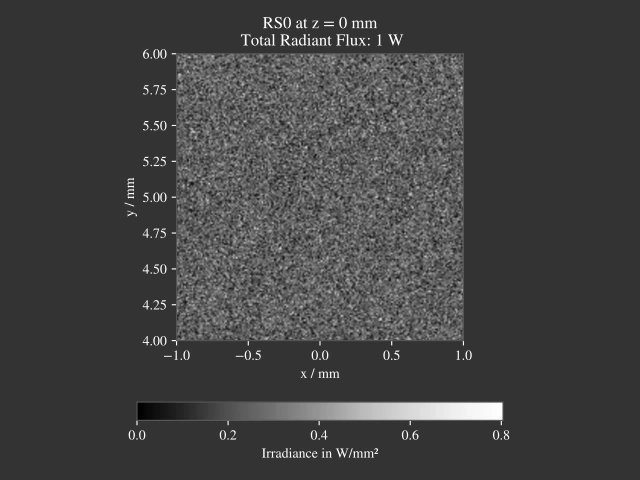
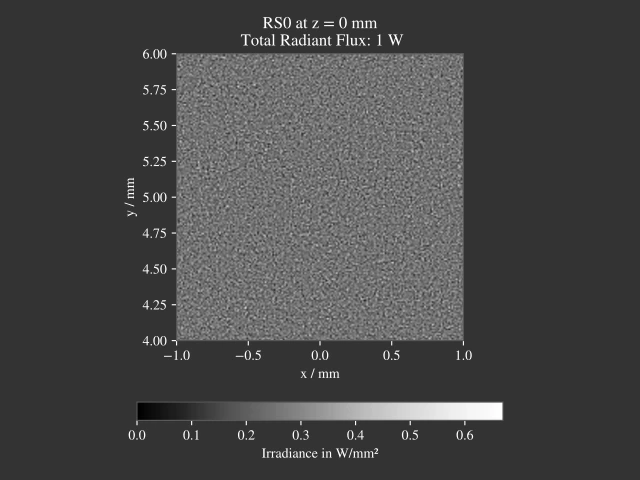
5.1.6. Disc/Annulus Sampling¶
Polar Grid Transformation Artifacts
Stratified sampling generates a rectangular grid, which needs to be transformed into a polar grid for disc sampling. While this is done uniformly in Section 5.9.4, there are some circular artefacts visible, especially at the center.
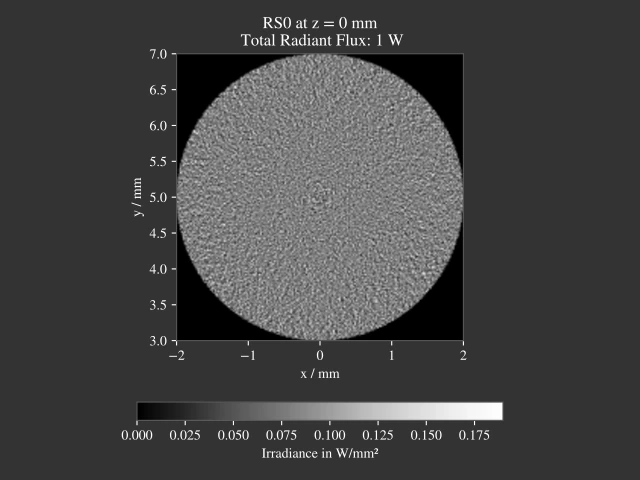
Fig. 5.3 200k rays with stratified sampling and a polar grid transformation as done in Section 5.9.4, image rendered with 189 x 189 pixel¶ |
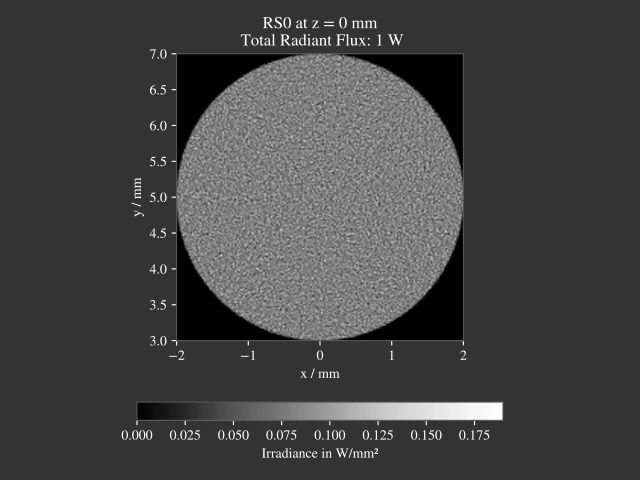
Fig. 5.4 200k rays on a circular area with positions mapped from stratified grid, image rendered with 189 x 189 pixel¶ |
These artifacts arise from the highly distorted rectangular cells that become circular sectors (such as pie slices). The rectangular cells are less distorted at the edge of the disc. In the inner region the area elements consist of small arc lengths and a large radial component, while going further outside the arc lengths increase and the radial lengths decrease. Near the center the area elements appear zoomed in. Such a grid and its distortion can be seen in [9], figure 5, as well as the figure above.
While for many rays the mentioned artefacts become less and less visible, a different approach is desirable. High quality data around the center is especially important, as in most cases it matches the region around the optical axis.
Square to Disc Mapping
One improved method is the Square-Disc Mapping method from [9]. optrace implements a simplified method from [10]. Sampled grid values \(x,~y\) lie inside a grid with bounds \(([-r_\text{o}, ~r_\text{o}], ~[-r_\text{o}, ~r_\text{o}])\) and are transformed to radial disc coordinates with:
Where \(r_\text{o}\) is the outer radius of the circle. Note that \(r\) has a sign, contrary to classic polar coordinates.
Disc to Annulus Mapping
When a annulus (surface between to concentric circles) is desired, the disc coordinates can be transformed by rescaling the radius \(r\) non-linearly. Section Section 5.9.4 describes how the linear values need to be inserted into a square function to achieve an equal-area mapping for a ring. The mapped radius \(r_\text{A}\) from an annulus with inner radius \(r_\text{i}\), outer radius \(r_\text{o}\) and radial coordinates \(r \in [0,~r_\text{o}]\) from (5.9) is then:
5.1.7. Power Sampling¶
The same power value is assigned to all rays. For multiple sources, the power ratio (each source has a power parameter) determines how the overall ray count is distributed amongst the sources. As the ray number can only be integer, but the power ratios arbitrary, the power ratio is not matched perfectly.
5.1.8. Polarization Sampling¶
For generating linear ray polarizations the procedure in Section 5.2.3 is applied. \(s = [0, 0, 1]\) is a vector parallel to the optical axis and \(s' \in \mathcal{S}\) from the directions generated above. The initial polarization \(E\) lies in the xy-plane and has some randomly distributed angle \(\mathcal{A}\) inside this plane.
Following this procedure, we get \(E'\), which is the polarization vector at the source.
The advantage of simulating the polarization vector like it would be behind a virtual lens can be demonstrated using the following example:
Generating ray vectors \(e_z = [0, 0, 1]\) with an polarization angle \(\alpha\). These rays get focused by an ideal lens, that has a well-defined focal point. Rays in this focal point have some vector distribution \(\mathcal{S}\) and a polarization distribution \(\mathcal{E}'\). The focal point can be seen as a point source.
Generating a point source with the same orientation vector distribution \(\mathcal{S}\) and polarization angle \(\alpha\) creates the same polarization distribution \(\mathcal{E}\)’ as in point 1. We can therefore omit this lens.
With this concept in mind, it now should be clear, what providing a fixed polarization angle or distribution means for different source ray directions.
The following angle distributions \(\mathcal{A}\) with \(\alpha \in \mathcal{A}\) are available:
x-Polarization |
\(\alpha = 0^{\circ}\) |
y-Polarization |
\(\alpha = 90^{\circ}\) |
Constant Angle |
\(\alpha = \alpha_0\) |
xy-Polarization |
\(\alpha\) randomly chosen from \(\{0^{\circ},~90^{\circ}\}\) |
Uniformly distributed |
\(\mathcal{A} = \mathcal{U}_{[0, ~2\pi]}\) |
User Function |
function \(f(\alpha)\)
\(\mathcal{A} = F^{-1}\left(\mathcal{U}_{[F(\alpha_0), ~F(\alpha_1)]}\right)\)
|
List |
angles \(A=\left\{\alpha_0, ~\alpha_1,~\dots\right\}\)
with probabilities \(P=\left\{p_0, ~p_1,~\dots\right\}\)
\(\alpha\) gets then chosen randomly from \(A\) according to \(P\)
|
5.1.9. Position Sampling¶
If a source image is specified, the positions are chosen randomly according to the effective intensity distribution of the image, see Section 5.8.5.
When no image is specified, positions are chosen randomly inside the source area, whereas the ray position probability density is uniformly random.
A Point source requires no sampling. 1D stratified sampling is employed for a Line source. A Rectangle surface is sampled by the 2D stratified sampling. For arbitrary rectangle aspect ratios the square sample grid cells become rectangular. A Circle or Ring surface get sampled according to the Disc/Annulus sampling section.
5.1.9.1. Spectrum Sampling¶
For a ray source with an sRGB image wavelengths are generated according to Section 5.8.5. In all other cases the wavelengths are chosen randomly according to a specified spectrum.
A Monochromatic type spectrum requires no random sampling. Sampling for Lines is implemented by a random selection of all wavelengths with weights proportional to their power. For types Constant and Rectangle the stratified 1D sampling is applied. Inverse transform sampling is applied for types User Function/ User Data / Blackbody.
A Gaussian type spectrum is truncated to allow only wavelength inside the visible spectrum range. \(\lambda\) is limited to \(\lambda \in [\lambda_l,~\lambda_r]\). For this function the anti-derivative integration bounds \(\xi_a,~\xi_b\) need to be calculated first before performing the inverse transform method.
Where \(\lambda_0\) is the center wavelength and \(\sigma_\lambda\) the standard deviation. With these bounds the random wavelengths are then:
5.1.10. Direction Cone¶
Modelling diffuse light emission is implemented by distributing ray directions around a base orientation \(s_0\). Rays are distributed around this vector inside a cone with half opening angle \(\theta_\text{max}\) with \(0 \leq\theta_\text{max} < \frac{\pi}{2}\). A direction vector \(s\) may have some opening angle \(\theta\) with \(0 \leq \theta \leq \theta_\text{max}\) and an angle \(\alpha\) inside the \(s_x,~s_y\)-plane perpendicular to the base cone orientation \(s_0\). However, \(s_x,~s_y\) are not parallel to the cartesian \(x,y,z\) axes, but arise from a vector multiplication of the cartesian axis and the base vector.

Fig. 5.5 Example direction vector \(s\) inside a cone volume around \(s_0\)¶
With \(x = [1, 0, 0]\) and \(s_0\) being the base orientation unity vector for the cone. The vectors \(s_x,s_y\) are calculated using vector products:
The ray direction \(s\) is composed of the base vector \(s_0\) and a perpendicular component \(s_r = s_x \cos \alpha + s_y \sin \alpha\). Keeping trigonometric relations in mind, the resulting vector is also a unity vector, like all the input vectors.
The corresponding random variables for \(\theta,~\alpha,~s\) are \(\Theta,~\mathcal{A},~\mathcal{S}\).
5.1.11. 2D Direction Sampling¶
For 2D direction sampling, ray directions are distributed inside a plane, which is a cross section of the cone in Section 5.1.10 including \(s_0\). Let \(\mathcal{A}\) be the random variable for \(\alpha\) with sample space \(\Omega_\alpha = \{\alpha_0, ~\alpha_0 + \pi\}\) that selects a half of this plane with equal probability for each side. While \(\mathcal{A}\) is equal for all elements, distribution \(\Theta\) differs according to the desired behavior:
Function
For a function \(f(\theta)\) with \(\theta \in [0, ~\theta_\text{max}]\) and \(0 < ~\theta_\text{max} \leq ~\frac{\pi}{2}\) we can apply the inverse sampling theorem (5.4):
Isotropic
Type Isotropic is a uniform distribution in all directions, which here just means:
Lambertian
A Lambertian radiator follows the cosine law. With \(f(\theta) = \cos \theta\), \(F(\theta) = \sin \theta\) and \(F^{-1}(F) = \arcsin(F)\) inverse transform sampling is performed:
5.1.12. 3D Direction sampling¶
For generating a full direction cone two random variables are required. To achieve a uniform, stratified and artefact free distribution, the disc mapping from Section 5.1.6 is applied. The random variable \(\mathcal{A}\) for values of \(\alpha\) is made of values of \(\theta\) from disc mapping. The second uniform variable \(\mathcal{U}\) is then the radius squared \(r^2\) and normalized by the squared disc radius.
Squaring is necessary as the values are uniformly distributed according to the area, but we need uniformly distributed values regarding the radius. The inverse transformation for this is known from Section 5.9.4. Rescaling this uniform variable into the desired output range is a simple linear transformation.
Function
Let \(f(\theta)\) be a user function with \(\theta \in [0, ~\theta_\text{max}]\) with \(0 < \theta_\text{max} \leq \frac{\pi}{2}\). In three dimensions \(f(\theta)\) needs to be scaled with \(\sin \theta\) for the distribution function, see [11] under Create samples on the hemisphere.
\(g(\theta)\) is then defined as \(g(\theta) := f(\theta) \sin \theta\). We can apply the inverse sampling theorem (5.4) on this new function:
Isotropic
With \(f(\theta) = 1\) we get \(g(\theta) = \sin \theta\) and \(G(\theta) = 1-\cos \theta\) and \(G^{-1}(G) = \arccos (1-G)\). Bounds are \(G \in [0, ~1-\cos \theta_\text{max}]\) and \(1 - G \in [1, ~\cos \theta_\text{max}]\). The latter is then swapped to ensure ascending bounds.
This is consistent with [12].
Lambertian
For \(f(\theta) = \cos \theta\) we get \(g(\theta) = \cos \theta \sin \theta\) and \(G(\theta) = \frac{1}{2} \sin^2 \theta\). The anti-derivative inverse is then \(G^{-1}(G) = \arcsin \sqrt{2G}\) with bounds \(\{0, ~\frac{1}{2}\sin^2 \theta_\text{max}\}\). A uniform random variable \(2G\) is then bound to \(\{0, \sin^2 \theta_\text{max}\}\).
For the angle distributions a form consistent with [13] is achieved:
References